 2017, Vol. ${metaVo.volume}
2017, Vol. ${metaVo.volume}文章信息
- 陈强, 何炎祥, 刘续乐, 刘健博
- CHEN Qiang, HE Yanxiang, LIU Xule, LIU Jianbo
- 交叉采样与结构情感融合的跨语言情感分析
- Cross-sampling and structural sentiment fusion based cross-lingual sentiment analysis
- 武汉大学学报(工学版), 2017, (2): 311-320
- Engineering Journal of Wuhan University, 2017, (2): 311-320
- http://dx.doi.org/10.14188/j.1671-8844.2017-02-026
-
文章历史
- 收稿日期: 2016-10-11





2. 武汉大学软件工程国家重点实验室,湖北 武汉 430072
2. State Key Lab of Software Engineering, Wuhan University, Wuhan 430072, China
近些年来,随着情感分析的商业价值不断提升,情感分析研究引起了越来越多人的关注.英语作为全世界最通用的语言之一,吸引了众多研究者的广泛兴趣,产生了大量高质量的英文情感资源,为情感分析在英语领域的快速发展打下了坚实的研究基础.由于情感分析发展的不均衡,导致了其他语言情感资源相对匮乏,使得情感分析在这些语言中的发展受到制约.而这一研究状况促使跨语言情感分析研究的诞生.跨语言情感分析(Cross-lingual Sentiment Analysis, CLSA)是利用一种语言的丰富情感资源来协助或者提高另一种语言的情感分析的一类研究.在跨语言情感分析中,具有丰富情感资源的语言(如英语)称为源语言,而情感资源相对匮乏的语言(如汉语、阿拉伯语等)被称为目标语言.
现有跨语言情感分析研究的主要思路:首先,建立源语言与目标语言之间的映射;然后,通过情感知识迁移方法将源语言的情感知识迁移到目标语言中,从而学习目标语言情感分析器.机器翻译是建立语言映射的最常用的方法[1-6].即使Duh等人断言通过机器翻译来建立语言间映射对于跨语言情感分析任务已经足够有效[7],但是不完美的机器翻译依旧阻碍了这类跨语言情感分析模型的表现.在前期的基础调研中发现即便Google翻译(Google在线翻译地址:http://translate.google.com, 被认为是最好的在线翻译服务之一)也同样不可避免地会改变翻译文本的情感极性,示例如下所示:

在基于N-gram特征空间的学习模型中,虽然训练数据在源语言中具有较高的可信性,但是由于源语言和目标语言之间的语言分布的不一致,使得情感知识迁移过程不可信.同样,机器学习过程本身存在不可避免的错误.然而,在训练数据规模较小的情况下,随着训练数据规模的增加,学习器性能会随之提升.因此,知识迁移、机器翻译和机器学习模型以及训练数据规模是决定学习性能上限的主要因素.
为了抵消知识迁移、机器翻译和机器学习模型导致的负面学习效应,本文旨于在传统协同学习框架中改变知识迁移中的采样策略,从而可以挖掘大量易得的未标注数据中高可靠的情感知识,最终学习出高质量目标语言情感分析器.同时,本文通过设定可信度阈值来控制迁移知识的质量,从而保证知识迁移学习过程的可信性.由于Choi和Saif等人均证明了运用深度语义信息可以进一步提高情感分析的准确性[8, 9],因而本文提出了利用带有句法结构的情感表达作为融合情感特征加入到传统N-gram特征空间中,进而促进协同学习情感知识的交互性和一致性,提高目标语言情感极性识别能力.
实验结果表明,相较于已有的跨语言情感分析工作,本文提出的基于交叉采样策略和融合情感的协同学习框架具有更好的性能.
1 相关工作 1.1 情感分析情感分析研究任务根据研究的语言粒度不同,分为:词级(lexicon-level)、超词级(aspect-level)、句子级(sentence-level)以及篇章级(document-level).本文工作属于篇章级情感识别研究,主要研究在线网络评论的情感极性判别问题.现有情感分析研究方法可以分为2类:基于情感词汇的统计方法和机器学习方法[10].
基于情感词汇统计的方法对情感词汇质量和数量具有极高的依赖性.Turney提出将句子或篇章中出现的所有情感词汇的平均情感值作为其对应情感值[11], 后续的研究者们也都采用了类似的想法在情感分析任务中[12, 13].基于机器学习方法训练监督或半监督的情感分类器对文本情感极性进行判断,该类方法一般针对具体情感分析任务形成人工特征后训练情感分类器.Pang等人比较了常用的分类器(NB、SVM和ME)在影评情感分析任务上的效果,发现SVM分类器具有最好的情感分析性能[14].Gamon证明结构语义可以进一步提升情感分类器[15].还有一些其他的机器学习方法被用于情感分析领域(例如工作)[16-19].
跨领域情感分析[20-24]与跨语言情感分析在本质上是一致的.然而,二者根本性的不同在于跨领域和跨语言的差别,语言的不同体现在语言特征、要素分布的不同,语言间的映射困难使得跨语言情感分析成为更大的挑战.
1.2 跨语言情感分析目前,跨语言情感分析方法可以归纳为2类:一类是集成学习的方法,通过“众包”思想将多个简单分类器合成性能更好的集成分类器;另一类是迁移学习方法,通过将源语言中的丰富的标注情感知识迁移到另外一种语言中,并基于迁移的知识训练获得目标语言情感分类器.
Wan首先提出用机器翻译的方法获得源语言对应的翻译文本,通过基于词汇统计方法和机器学习方法按照语言-方法模式训练4个基本分类器,最后通过加权投票方式合成目标语言情感分类器[1].然而,随着半监督学习方法的发展,迁移学习被更多地应用到跨语言情感分析领域,并更多关注知识适应性研究.例如Wan将2种语言视为2个相互冗余的视图,然后采用半监督的协同学习框架来迭代地对知识进行交互迁移从而达到交互学习的目的[3].Chen等人同样将源语言和目标语言看成2个视图,但是在每个视图中都加入了Boosting技术来进行知识适应,并且在源语言向目标语言进行单向知识迁移过程中加入了知识验证和适应性识别过程,进一步保证了迁移知识可信性和适应性,达到更好的目标语言情感极性识别能力[6].跨语言情感分析研究中其他的迁移学习方法还包括工作[4, 5, 25].以上方法均采用机器翻译构建语言间映射,通过知识迁移来实现源语言对目标语言情感知识输出.
与此同时,其他的一些机器学习方法通过从非标注平行语料中获取语言间的映射.如Meng等人利用非监督学习方法从非平行语料发现未观察到的情感词,通过提高情感词的识别覆盖率达到增强语言间映射关系的目的[26].Popat等人使用非标注平行语料对训练特征进行聚类,从而减小特征空间表达的稀疏性,增强源语言与目标语言特征间的映射命中率[27].Xiao等提出了一种2阶段矩阵填充的方法,该方法利用额外的非标注平行语料实现半正定矩阵的半监督填充,从而自动发现语言间的特征关联[28].这些方法都是利用额外的非标注的平行语料来增强或构建语言间的映射,然而特定领域的平行语料同样是稀缺资源,因此这些方法的实用性较差.
2 跨语言情感分析学习框架在协同学习框架下,本文提出在选择迁移知识时采用交叉采样的策略.交叉采样策略优势包括:1) 发现大量易得的未标注数据中的情感知识并交互迁移,以平衡由于机器翻译和错误分类导致的错误知识迁移而产生的负面学习效应;2) 在源语言部分,基于标注的翻译训练数据的情感分类器可以对未标注原数据进行预测,一定程度上保证了知识迁移过程的可靠性;3) 大量的未标注源语言数据的应用,使得对源语言标注数据的规模要求的适度降低,保证了该学习框架的实用性和推广性.
为得到更高效的学习效果,本文在传统的特征空间中加入结构情感信息,使得特征空间更具情感表征能力.同时,在跨语言交互学习中,由于伪平行文本是通过机器翻译进行映射的,因而,更大粒度的结构情感信息具有更准确的映射对齐性,保证协同学习过程中源语言和目标语言间具有更大的冗余,保证交互学习的性能.
本文的跨语言情感分析问题描述如下:
1) 语言视图.英文视图为源语言视图,中文视图为目标语言视图.
2) 训练数据.小规模的标注英文商品评论Len,大量未标注英文评论Uen以及未标注中文评论Ucn.
3) 数据预处理.通过Google在线翻译,将所有英文评论翻译成中文,同样将中文评论翻译成英文,得到伪标注中文评论Lcn(MT)、伪中文未标注评论Ucn(MT)、伪英文未标注评论Uen(MT),这样就组成了3组伪平行评论集合{Len, Lcn(MT)}、{Uen, Ucn(MT)}和{Uen(MT), Ucn}.
4) 情感资源.标准英文MPQA情感词典,通过金山在线翻译服务获得其对应中文标准情感词集.
5) 跨语言情感分析任务.通过以上数据集和情感资源学习中文情感分类器.
2.1 交叉采样的协同学习框架跨语言情感分析协同学习框架的实验结果说明信息的交互学习对于参与学习的2种语言都有较好的性能提升[3](本文称之为基础协同学习框架).基础协同学习框架存在明显的问题,即其采样策略使得知识迁移过程不可靠,且适应性不强.本文在基础框架中引入交叉采样策略对跨语言情感知识进行交互指导学习,该框架在本文中称之为交叉采样的交互学习框架(Cross-sampling Mutual-learning Framework, CMF).
2.1.1 训练过程在CMF中,英文和中文分别看成2个冗余的语言视图.
在第(t)轮训练中,中文视图(英文视图)中的未标注数据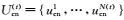
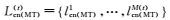
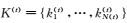
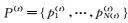
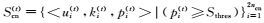
在第(t)轮训练中,英文视图中的未标注数据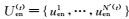
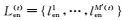
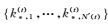
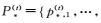
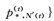
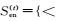
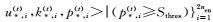
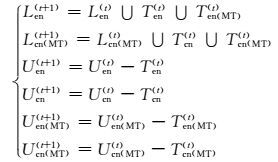 (1)
(1)
将第(t)轮训练中选择的迁移知识Tcn(t)和Ten(t)分别在伪平行数据{Uen(MT), Ucn}和{Uen, Ucn(MT)}映射获得对应迁移知识Ten(MT)(t)和Tcn(MT)(t)后,根据式(1) 对所有训练数据进行更新.在本文中,CMF从第(0) 轮开始训练,且数据集初始化为: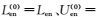
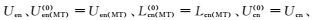
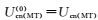
从CMF框架可以看出:1) 交叉选择策略可以通过学习源语言视图中未标注语料的情感知识并迁移到目标语言视图中,用以补偿由于其他因素导致的负面学习影响;2) 在各语言视图中,分类器仅对本语言的原文本(相较于翻译文本)进行预测,确保了预测结果的可靠性,保证了迁移知识的质量;3) 在进行迁移知识采样时,通过设置置信阈值进一步保证迁移知识的质量.CMF的以上优点保证了最终训练的中文情感分类器的性能.
| 算法1 CMF框架(训练) |
| Training: |
| While t≤T,do: |
| Step 1:由英文标注数据Len(t)训练分类器Cen(t). |
| Step 2:用英文情感分类器Cen(t)标注英文未标注数据Uen(t),选择具有较高置信值的2ncn个(即pi(t)≥Sthres)候选样本Scn(t)作为迁移知识Tcn(t),并通过伪平行数据集{Uen(MT), Ucn}映射成翻译知识Ten(MT)(t)添加到英文训练数据集Len(t+1). |
| Step 3:由伪中文标注数据Lcn(MT)(t)训练分类器Ccn(t). |
| Step 4:用中文情感分类器Ccn(t)标注中文未标注数据Uen(t),选择具有较高置信度的2nen个(即p*, i(t)≥Sthres)候选样本Sen(t)作为迁移知识Ten(t),并通过伪平行数据集{Uen, Ucn(MT)}映射成翻译知识Tcn(MT)(t)添加到中文训练数据中Lcn(MT)(t+1). |
| Step 5:根据式(1) 对所有数据集进行更新. |
| End While. |
| Return:跨语言情感极性分类器Cen(T)和Ccn(T). |
跨语言情感分析任务的目标是训练目标语言情感分类器Ccn(T),而Wan证明跨语言情感分类器的集成可以进一步提升情感分析的性能[1, 3].在此基础上,本文在预测阶段同样采用集成分类器.由于目标语言分类器对原数据进行预测,而源语言分类器对翻译数据进行预测.因此,2个视图的预测可靠性存在偏倚:源语言分类器的预测更可靠,而目标分类器的预测存在风险.因此,本文采用置信偏倚的投票策略集成跨语言情感极性分类器,具体预测过程为:对某一条目标语言评论ricn,翻译获得伪源语言评论rien(MT);分别用分类器Ccn(T)和分类器Cen(T)预测评论ricn和伪评论rien(MT)情感极性标签ki(T)和k*, i(T),并给出预测置信值pi(T)和p*, i(T);设置集成分类器置信偏倚值Cthres.具体地,如果pi(T)+Cthres≥p*, i(T),那么评论ricn的最终情感极性预测为ki(T),否则为k*, i(T).
整个CMF框架流程图如图 1所示.具体预测过程如算法2所述.

|
| 图 1 交叉采样的交互学习框架 Figure 1 Cross-sampling based mutual-training framework |
| 算法2 CMF框架(预测) |
| Predicting: |
| Step 1:翻译中文评论ricn成英文rien(MT). |
| Step 2:用Ccn(T)和Cen(T)分别预测ricn和rien(MT)情感极性ki(T)和k*, i(T),并给出预测置信度pi(T)和p*, i(T). |
| Step 3:If pi(T)+Cthres≥p*, i(T): Then情感标签ki(T). |
| Else: Then k*, i(T). |
由于传统n-gram特征在情感表达上的局限性,如词无序性、无结构性(包括无语义和语法结构)等.在情感分析中,结构情感信息可以提高情感分析的准确性.因此,本文将结构情感信息(情感表达)加入传统的n-gram特征空间中,生成情感表征性更强特征空间.融合结构情感特征的CMF,称之为交叉采样和结构情感融合的交互学习算法(简称为SCMA).本文中的结构情感信息(即情感表达式,在算法描述部分均称为情感短语)是一种基于句法分析的启发式情感表达式抽取方法,具体抽取过程如下.
2.2.1 资源准备资源包括标准MPQA英文情感词典、中英文常用转折词典、常用否定词集和程度词典,翻译的MPQA中文情感词典.
2.2.2 数据预处理将所有评论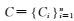 按照标点符号进行分句
按照标点符号进行分句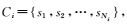 再利用Stanford Parser(在线Stanford Parser地址:http://nlp.stanford.edu:8080/parser/.)将句子进行句法解析并保存到对应评论
再利用Stanford Parser(在线Stanford Parser地址:http://nlp.stanford.edu:8080/parser/.)将句子进行句法解析并保存到对应评论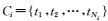 (其中tj是sj的句法树)中.
(其中tj是sj的句法树)中.
初始化情感短语库SPDic=∅,对tj做如下处理:
步骤(1) 按tj中词从左至右顺序依次查询情感词典SDic,发现第1个情感词SW,按照树结构找到其直接父节点SW↑;检查以SW↑为根节点的子树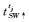
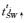
步骤(2) 执行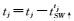
对于某一评论中句子所包含的情感短语的抽取流程如算法3所描述.对某一种语言视图中情感短语库的构建流程如图 2所示.
3 实验及分析 3.1 实验数据及评价方法本文的实验数据为公开数据集,来自NLP&CC2013(NLP&CC 2013由CCF主办、由重庆大学和数字出版技术国家重点实验室承办.其中任务3为跨语言情感分析任务.更多信息,请访问:http://tcci.ccf.org.cn/conference/2013/.)中的跨语言情感分析评测任务.数据主要由自亚马逊的中英文商品评论,覆盖Books、DVD、Music 3个领域.其中,3个领域的训练数据均包含4 000标注英文评论,以及各领域数据集分别包含17 814、47 071、29 677条未标注中文评论,均包含4 000条测试数据作为评测依据.由于CMF的假设中包含利用定量未标注英文数据假设,因此在实验中所采用的数据设定如表 1所示.
| Domain | English | Chinese | |||
| L | U | L | U | ||
| Books | Train | 2 000 | 2 000 | 2 000 | |
| Test | 4 000 | ||||
| DVD | Train | 2 000 | 2 000 | 2 000 | |
| Test | 4 000 | ||||
| Music | Train | 2 000 | 2 000 | 2 000 | |
| Test | 4 000 | ||||
| 算法3 结构情感信息抽取 |
| Extracting: |
| Step 1:初始化情感短语库SPDic=∅. |
Step 2:对句子sj的句法树tj查询SDic,发现情感词SW,搜索SW直接父节点SW↑,检查以SW↑为根节点的子树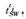 中是否存在非SW的其他情感元素,若存在,令SW=SW↑,执行步骤2,否则,执行步骤3. 中是否存在非SW的其他情感元素,若存在,令SW=SW↑,执行步骤2,否则,执行步骤3. |
Step 3: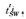 句子中的词序列SP作为情感短语,检查SPDic中是否存在SP,若存在,舍弃SP,否则,将其加入情感短语库中SPDic←SPDic∪{SP},执行步骤4. 句子中的词序列SP作为情感短语,检查SPDic中是否存在SP,若存在,舍弃SP,否则,将其加入情感短语库中SPDic←SPDic∪{SP},执行步骤4. |
Step 4:令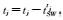 ,检查tj=∅,若成立,则停止,否则,执行步骤2. ,检查tj=∅,若成立,则停止,否则,执行步骤2. |

|
| 图 2 带树结构的情感特征抽取流程 Figure 2 Process of tree-structured sentiment feature extraction |
对于测试数据的预测有4种可能,如表 2所示.实验评估方法为标准的准确率、召回率和F1值,实验综合评估为领域平均准确率:
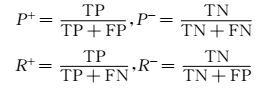 (2)
(2)
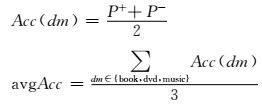 (3)
(3)
| Classification | Predicted Pos. | Predicted Neg. |
| Actual Pos. | TF | FN |
| Actual Neg. | FP | TN |
为了更好说明CMF和SCMA的有效性,本文将CMF和SCMA方法与以下基准方法进行比较:
1) 基于情感统计的方法(Lexicon-based).对中文评论统计翻译的中文MPQA情感词典、少量常用中文的转折词、否定词和程度副词并设定评分标准,评分预测中文情感极性.
2) 评测最佳系统(Best-report).NLP & CC 2013评测会议中跨语言情感分析任务中最好结果的评测结果.
3) 基础SVM方法(SVM-EN2CN).将标注英文翻译成中文,使用unigram特征空间训练SVM中文情感分类器.
4) 基础SVM方法(SVM-CN2EN).将测试数据翻译成英文,使用unigram特征空间训练SVM英文情感分类器.
5) 基础协同学习方法(Co-Train).Wan提出的跨语言情感分析协同学习框架[3].
6) 改进的协同学习方法(Ad-Co-Train).在Co-Train方法基础上,在每次迭代过程中加入采样置信度阈值来控制迁移知识的可靠性,同时,在预测部分的分类器集成中采用带有偏倚的投票策略,其中,Sthres=0.90,Cthres=0.14.
在所有方法中,特征空间由unigram特征构成,基础分类器均采用SVM分类.基准方法实际分类器训练中,使用LibSVM工具包的线性SVM模型,且参数为默认设置.此外,本文提出的方法分别同时又采用LibLinear工具包中的线性分类器,分别称为CMF(LibSVM)、CMF(LibLinear)、SCMA(LibSVM)、SCMA(LibLinear).
3.3 实验结果及分析本文方法有4个主要参数影响其性能,分别是采样规模nen和ncn、采样置信度阈值Sthres、分类器集成置信度偏置Cthres.参数选择采用网格搜索的方法通过大量实验搜索较优的参数设置.首先,设定参数Cthres=0.0,nen=ncn=5,从经验值集合{0.0, 0.85, 0.86, …, 0.95}中搜索最优的Sthres;其次,再固定最优的Sthres,设定nen=ncn=5,从经验值集合{-0.20, -0.19, …, 0.0, …, 0.19, 0.20}中寻找最优的Cthres;最后,固定最优的Sthres和Cthres,搜索最优的(nen, ncn).最终模型的参数设置如表 3所示.
| Domain | Sthres | Cthres | nen | ncn |
| Books | 0.87 | 0.14 | 10 | 15 |
| DVD | 0.90 | 0.14 | 10 | 15 |
| Music | 0.90 | 0.04 | 10 | 15 |
所有方法的实验结果如表 4所示.实验结果表明,相较于前4种基础学习方法,协同学习方法具有更好的学习性能.跨语言间的知识交互迁移过程可以更好地实现中英文间的知识迁移和分享:中文视图对迁移的英文情感知识进行适应性学习并挖掘出对应中文情感知识,同时英文视图接受并逐渐学习中文情感知识.该过程不断重复,最终达到中英文视图间情感知识交互学习的目的.
| Method | Accuracy | |||
| Books | DVD | Music | Average | |
| Lexicon-based | 0.770 0 | 0.783 2 | 0.759 5 | 0.770 9 |
| Best-report | 0.785 0 | 0.777 3 | 0.751 3 | 0.771 2 |
| SVM-CN2EN | 0.699 8 | 0.705 0 | 0.664 5 | 0.689 8 |
| SVM-EN2CN | 0.787 5 | 0.777 0 | 0.741 2 | 0.768 6 |
| Co-Train | 0.804 5 | 0.778 2 | 0.748 0 | 0.776 9 |
| Ad-Co-Train | 0.813 5 | 0.807 5 | 0.768 0 | 0.796 3 |
| CMF(LibSVM) | 0.815 0 | 0.816 2 | 0.787 5 | 0.806 2 |
| CMF(LibLinear) | 0.834 5 | 0.831 5 | 0.800 0 | 0.822 0 |
| SCMA(LibSVM) | 0.825 5 | 0.824 8 | 0.801 8 | 0.817 4 |
| SCMA(LibLinear) | 0.843 5 | 0.850 0 | 0.813 0 | 0.835 5 |
在表 4的实验结果中,比较SVM-CN2EN和SVM-EN2CN方法可以看出:由于最终的目标是对中文进行情感预测,因而,训练出的中文分类器的性能相较于英文分类器更加可靠,进一步证明了本文采取带有置信偏倚的分类器集成策略的合理性.同样,比较Co-Train和Ad-Co-Train方法,发现采样置信度阈值的设定可以在一定程度上提升迁移知识的可信性.
对比CMF方法和Co-Train、Ad-Co-Train方法,可以发现交叉采样策略可以通过半监督学习的方式不断发现大量易得的未标注英文评论中的高质量情感知识并迁移到中文学习器中,很大程度上弥补由于其他不可抗拒因素带来的负面学习影响,从而提高了中文情感分类器性能.同样,从SCMA方法和CMF方法的实验结果,证明更具表征能力的结构情感信息(情感短语)使得中英文视图间的交互学习更加有效,进一步加强了跨语言情感分类器的性能.
图 3为不同采样置信度阈值条件下,CMF和SCMA方法随着迭代次数增加的性能变化曲线.从图中可以发现,当采样置信度阈值接近0.90时,基于CMF和SCMA的系统性能达到最优.并且,随着采样置信度阈值逐渐增大,可能系统对知识的审核过度严谨,使得真正发生迁移的知识减少,从而阻碍了交互学习的程度;然而,随着采样置信度阈值逐渐减小,系统可能引入大量不可信的知识,给学习过程带来较大的负面影响.

|
| 图 3 不同采样置信度阈值下的性能变化曲线 Figure 3 Curves of performance variations with different sampling confidence thresholds |
图 4为不同采样规模下,SCMA方法的性能随着迭代次数变化而变化的曲线.从图中可以发现:当采样规模设定中文为15、英文为10时,系统性能表现较好;当采样规模较小时,由于系统每次迭代学习过程中获得不到足够的情感知识用以抵消其他因素导致的负面学习影响,使得性能表现较差;同时,相似采样规模的系统比较,可以发现在每次迭代中采样较多的中文知识时,系统性能表现较好,这进一步说明了在目标语言为中文时,最终分类器更加依赖中文情感知识的学习.

|
| 图 4 不同采样规模下的性能变化曲线 Figure 4 Curves of performance variations under different sampling scales |
图 5为以不同置信偏倚值集成分类器时,不同领域中系统性能的变化曲线.图中曲线说明具有正的置信偏倚值的集成分类器具有较高的预测性能.并且,系统在不同领域中具有一致的最优集成置信度偏倚值,充分验证了本文提出的带有置信偏倚的分类器集成假设.

|
| 图 5 不同分类器集成置信偏倚下的模型性能变化曲线 Figure 5 Curves of performance variations under different classifier combination bias thresholds |
同样,实验结果显示在最优的参数值的一定范围内,系统的性能变化较为平稳,证明了本文提出方法的有效性和实用性.
4 结语本文在传统跨语言情感分析协同学习框架的基础上,提出了采用交叉采样策略和结构情感信息融合的跨语言情感分析交互学习框架.该框架进一步将跨语言情感分析准确率提高了4.05%.
在将来的工作中,会在该学习框架中引入大规模的中英文未标注数据,探索系统性能与未标注数据规模直接的关系,并且引入Chen等人提出的知识验证策略更准确地对迁移知识的可信性进行验证[6].
| [1] | Wan X. Using bilingual knowledge and ensemble techniques for unsupervised Chinese sentiment analysis [C]// Pado S. Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing. Honolulu, Hawaii, USA: Association for Computational Linguistics, 2008: 553-561. |
| [2] | Banea C, Mihalcea R, Wiebe J et al.. Multilingual subjectivity analysis using machine translation [C]// Pado S. Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing. Honolulu, Hawaii, USA: Association for Computational Linguistics, 2008: 127-135. |
| [3] | Wan X. Co-training for cross-lingual sentiment classification [C]// Regina B, Chang J. Proceedings of the 47th Annual Meeting of the ACL and the 4th IJCNLP of the AFNLP. Suntec, Singapore: Association for Computational Linguistics, 2009: 235-243. |
| [4] | Wei B, Pal C. Cross lingual adaptation: an experiment on sentiment classification [C]// Chang J, Koehn P. Proceedings of the 48 Annual Meeting of the Association for Computational Linguistics. Uppsala, Sweden: Association for Computational Linguistics, 2010: 258-262. |
| [5] | Gui L, Xu R, Lu Q, et al. Cross-lingual opinion analysis via negative transfer detection [C]// Koller A, Yusuke M. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (short paper). Baltimore, Maryland, USA: Association for Computational Linguistics, 2014: 860-865. |
| [6] | Chen Q, Li W, Lei Y, et al. Learning to adapt credible knowledge in cross-lingual sentiment analysis [C]// Che W, Zhou G. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing, China: Association for Computational Linguistics, 2015: 419-429. |
| [7] | Duh K, Dujino A, Nagata M. Is machine translation ripe for cross-lingual sentiment classification [C]// Zhou G. Proceedings of the 49 Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Portland, Oregon, USA: Association for Computational Linguistics, 2011: 429-433. |
| [8] | Choi Y, Cardie C. Learning with compositional semantics as structural inference for subsentential sentiment analysis [C]// Pado S. Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing. Honolulu, Hawaii, USA: Association for Computational Linguistics, 2008: 792-801. |
| [9] | Saif H, He Y, Alani H. Semantic sentiment analysis of Twitter [C]// Blomgvist E. Proceedings of the 11th International Semantics Web Conference ISWC 2012. Verlag Berlin, Heidelberg: Springer, 2012: 508-524. |
| [10] | Liu B. Sentiment Analysis and Opinion Mining[M]. Morgan & Claypool Publisher, 2012:41-43. |
| [11] | Turney P D. Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews [C]// Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Philadelphia, PA, USA: Association for Computational Linguistics, 2002: 417-424. |
| [12] | Hiroshi K, Tetsuya N, Hideo W. Deeper sentiment analysis using machine translation technology [C]// Proceedings of International Conference on Computational linguistics COLING. Switzerland: Association for Computational Linguistics, 2004: 494-500. |
| [13] | Kennedy A, Inkpen D. Sentiment classification of movie reviews using contextual valence shifters[J]. Computational Intelligence, 2006, 22(2): 110–125. DOI:10.1111/coin.2006.22.issue-2 |
| [14] | Pang B, Lee L, Vaithyanathan S. Thumbs up? sentiment classification using machine learning techniques [C]// Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing. Philadelphia, PA, USA: Association for Computational Linguistics, 2002: 79-86. |
| [15] | Gamon M. Sentiment classification on customer feedback data: noisy data, large feature vectors and the role of linguistic analysis [C]// Proceedings of the 20th International Conference on Computational Linguistics COLING. Switzerland: Association for Computational Linguistics, 2004: 841-847. |
| [16] | Read J. Using emotions to reduce dependency in machine learning techniques for sentiment classification [C]// Eisner J, Koehn P. Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics Student Research Workshop. New York, USA: Association for Computational Linguistics, 2005: 43-48. |
| [17] | Hassan A, Radev D. Identifying text polarity using random walks [C]// Chang J, Koehn P. Proceedings of the 48th Annual Meeting on Association for Computational Linguistics. Uppsala, Sweden: Association for Computational Linguistics, 2010: 395-403. |
| [18] | Socher R, Perelygin A, Wu J Y, et al. Recursive deep models for semantics compositionality over a sentiment treebank [C]// Bethard S. Proceedings of the Conference on Empirical Methods in Natural Language Processing. Seattle, USA: Association for Computational Linguistics, 2013: 1631-1642. |
| [19] | Lv P, Zhong L, Cai D, et al. OHRank: an algorithm integrating mentality and influence of opinion holder for opinion mining[J]. Chinese Journal of Electronics, 2013, 22(4): 655–660. |
| [20] | Tan S, Wu G, Tang H, et al. A novel scheme for domain-transfer problem in the context of sentiment analysis [C]// Proceedings of the 16th ACM Conference on Information and Knowledge Management. Lisbon, Portugal: ACM, 2007: 979-982. |
| [21] | Li T, Sindhwani V, Ding C, et al. Knowledge transformation for cross-domain sentiment classification [C]// Smucker M D. Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. Boston, MA, USA: ACM, 2009: 716-717. |
| [22] | Pan S J, Yang Q. A survey on transfer learning[J]. IEEE Transactions on Knowledge Data Engineering, 2010, 22(10): 1345–1359. DOI:10.1109/TKDE.2009.191 |
| [23] | He Y, Lin C, Alani H. Automatically extracting polarity-bearing topics for cross domain sentiment classification [C]// Zhou G. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Portland, Oregon, USA: Association for Computational Linguistics, 2011: 123-131. |
| [24] | Glorot X, Bordes A, Bengio Y. Domain adaptation for large-scale sentiment classification: A deep learning approach [C]// Ⅲ Daume H, Kilian Weinberger. Proceedings of the 28th International Conference on Machine Learning. Bellevue, Washington, USA, 2011: 513-520. |
| [25] | He Y. Latent sentiment model for weakly-supervised cross-lingual sentiment classification [C]// Lee H. Proceedings of 33rd European Conference on Information Retrieval (ECIR 2011). Dublin, Ireland: Springer, 2011: 214-225. |
| [26] | Meng X, Wei F, Liu X, et al. Cross-lingual mixture model for sentiment classification [C]// Li M, White M. Proceeding of the 50th Annual Meeting of the Association for Computational Linguistics. Jeju Island, Korea: Association for Computational Linguistics, 2012: 572-581. |
| [27] | Popat K, Balamurali A R, Bhattacharyya P, et al. The haves and the have-nots: leverage unlabeled corpora for sentiment analysis [C]// Navigli R, Chang J. Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia, Bulgaria: Association for Computational Linguistics, 2013: 412-422. |
| [28] | Xiao M, Guo Y. Semi-supervised matrix completion for cross-lingual text classification [C]// Kambhampati S. Proceedings of the 28th AAAI Conference on Artificial Intelligence. Quebec City, Quebec, Canada: AAAI Press, 2014: 1607-1613. |